Episode 1, season 1 – Define your model type for a proprietary architecture
📅 Published on July 30, 2024
This article marks the beginning of an exciting summer series where we will guide you through creating your own proprietary model architecture. This series will culminate in the release of two open-source models: Elektra (combining MLOps, DevOps, and cybersecurity) and Turing (focusing on Product Ownership and Project Management).
I. About us
We have extensive experience in developing AI models, having worked on over 26 production models for clients (serving as the architects for 11 of them) and creating 14 proprietary models for our own needs. One of these models is commercialized as a Model as a Service (MaaS), reflecting a new business model in the AI industry. This year alone, our team has developed six proprietary LLM-based models: Aurélia, Adriana, Nakamoto, Pr Violet, Turing, and Elektra.
To stay current and enhance our knowledge, we read two new research papers daily. We encourage you to share your insights relevant to the topics we cover.
II. Step 1: Determine your type of model
The first step in creating your proprietary model is determining the type of model you need. Here are the main categories:
- Automation models: These models are typically connected to agents that automate tasks.
- Interaction models: Personalized expert interactive AI, often referred to as “chatbots,” but offering much more.
- Correction models: Used for data treatment or correcting any input, like the French AI teacher, Pr Violet.
III. Step 2: Understand the components based on the model type
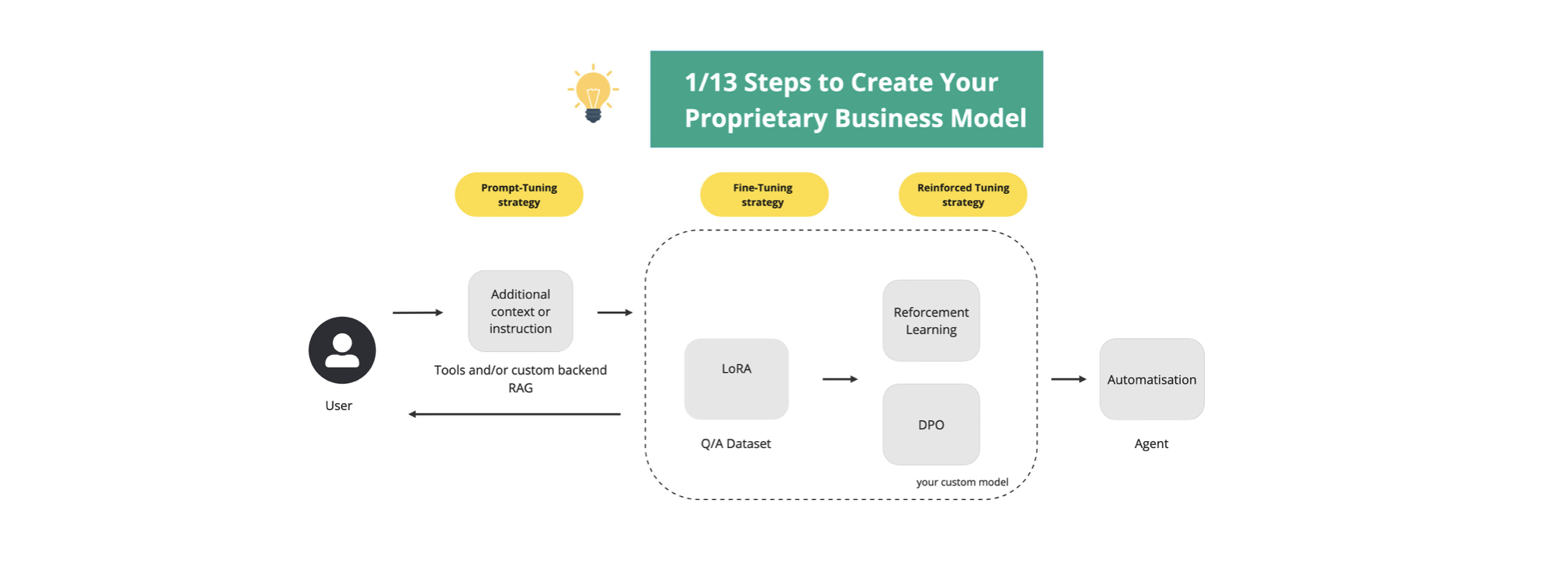
Once you’ve identified your model type, you need to understand the necessary components. Here are some strategies and tools to consider:
1. Prompt-tuning strategy
- Purpose: Customize user prompts to enhance inference.
- Tools and custom backend: Use custom backends for business accuracy and control.
- RAG (Retrieval-Augmented Generation): A contextualization strategy using vector databases and graph data as intermediaries.
2. Fine-tuning strategy
- LoRA (Low-Rank Adaptation): Fine-tune open-source models for better accuracy.
3. Reinforced tuning strategy
- Reinforcement Learning (RL): Typically, RLHF (Reinforcement Learning with Human Feedback) is used for LLMs to improve models based on feedback. We use automated RL.
- DPO (Direct Preference Optimization): A straightforward reinforcement learning approach.
4. Agent
- Role: Similar to the agent in The Matrix, it detects and corrects anomalies in the system or automates tasks.
IV. Future sessions
In the upcoming sessions, we will detail the architectures of our models and the components used for each use case. Additionally, we will provide insights into well-known projects, giving you a comprehensive understanding of model architecture design and implementation.
(1) Discriminator in GANs: Here, a discriminator refers to its role in a Generative Adversarial Network (GAN), where it detects issues and helps improve the primary model by generating the retraining process.
Join us as we embark on this journey to create robust and innovative AI models, leveraging cutting-edge strategies and tools to build solutions that can transform your business and industry.