Mastering RAG with Knowledge Graphs
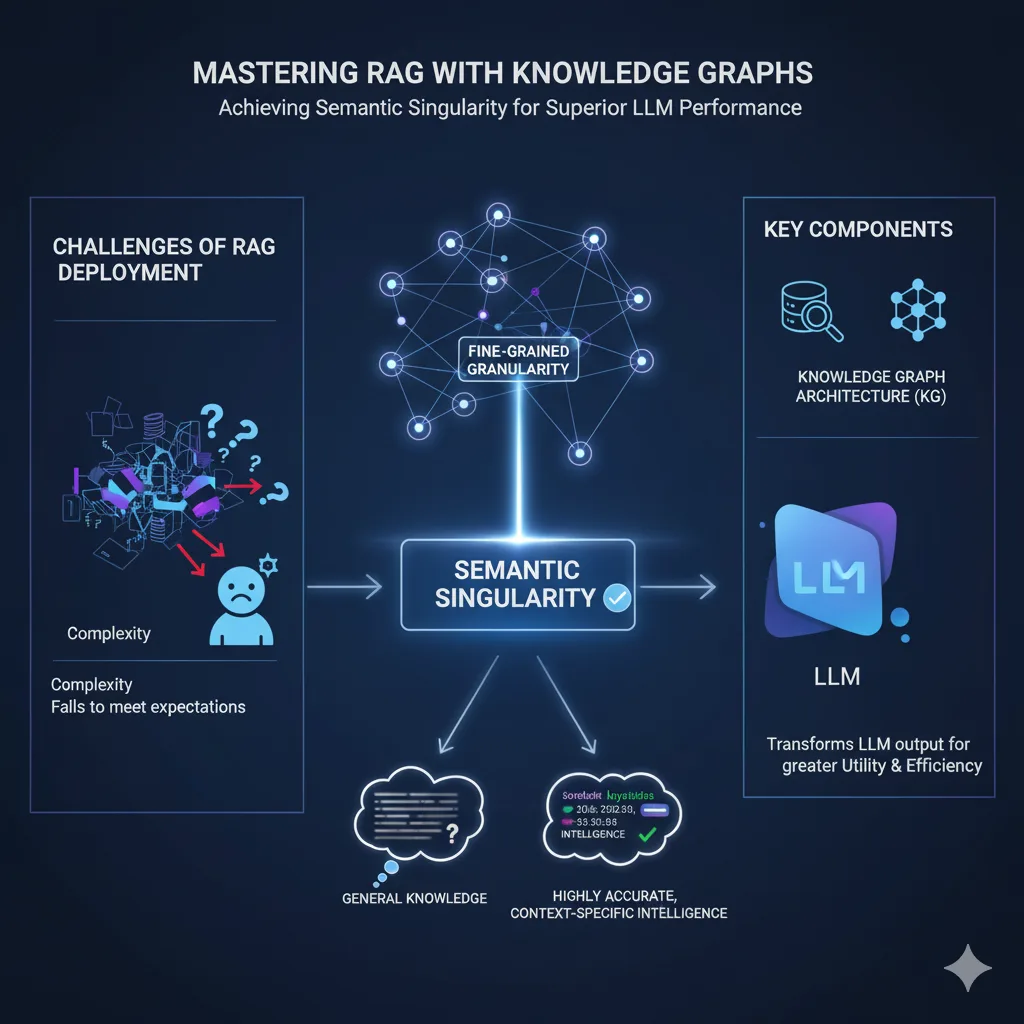
The implementation of Retrieval-Augmented Generation (RAG) often faces skepticism. Many practitioners report difficulties. Common feedback suggests RAG deployment is complex or fails to meet initial expectations. Indeed, RAG is not inherently flawed. Its effectiveness depends entirely on the underlying data structure. The true measure of success lies in achieving semantic singularity. This precise outcome is unlocked through the application of fine-grained granularity within a Knowledge Graph (KG) architecture. This approach successfully transforms LLM output from general knowledge into highly accurate, context-specific intelligence.
 Understanding Retrieval-Augmented Generation (RAG)
Understanding Retrieval-Augmented Generation (RAG)
RAG serves a critical function. It grounds Large Language Models (LLMs) in external, proprietary, or highly specialized data. This process mitigates the risk of hallucination. It also ensures the model’s responses are verifiable and current. The RAG mechanism follows four necessary steps, regardless of the database technology utilized:
- Content Segmentation (Chunking): Source documents are divided into smaller, manageable text segments.
- Indexing: These segments are processed and stored. The indexing method determines the retrieval strategy.
- Retrieval: The user query is used to fetch the most relevant segments from the index. Retrieval can happen by similarity or by specific labels.
- Context Injection: The retrieved segments are injected into the LLM’s input prompt. The LLM then generates a response based on this augmented context.
Vector database approaches can perform adequately in certain scenarios. Specifically, they work well when the source content is very clean and the indexing is optimally configured. However, their fundamental architecture introduces strategic limitations.
The Inherent Limitations of Vector-Based RAG
The primary challenge with vector-only approaches is informational noise. Vector databases represent text chunks as numerical vectors. These vectors map semantic similarity. This system struggles to capture specific, explicit relationships. These critical links are often blurred or lost in the dense vector space. Thus, the LLM must imperfectly deduce relationships from text proximity alone. This deduction introduces error and reduces precision.
This problem is particularly acute for essential business and corporate relationships. Specific examples highlight this limitation:
- Business-Specific Context: A regulation’s precise applicability to a specific machine component. The link is categorical, not just semantic.
- Company-Specific Assets: The critical relationship “Product X is manufactured at Plant Z” is often obscured.
- Organizational Structure: The vital link “Product X’s communication is managed by Department W” becomes difficult to reliably extract.
These factual, relational links are critical for actionable business intelligence. They are often drowned out or misinterpreted when only using vector similarity. A more structured, explicit encoding mechanism is therefore required.
Knowledge Graphs with The Architecture of Semantic Singularity
A Knowledge Graph (KG) fundamentally solves the problem of informational noise. A KG explicitly models information through nodes (entities), edges (relationships), and properties. This structure creates a rich, contextual network. Indeed, a KG allows the construction of a true reasoning schema.
The KG approach achieves semantic singularity. This means the retrieved information is not merely relevant; it is perfectly precise and contextually complete for the query’s intent. This precision is driven by two mechanisms:
- Highly Precise Chunking: Information is broken down into succinct, atomic statements (as short as possible).
- Multi-Label Granularity: Each statement (node) is tagged with multiple specific labels. This labeling provides fine-grained contextual categorization.
The relationships linking these precise pieces of information create the necessary reasoning path. This network is nearly impossible for purely vector-based systems to match consistently. Therefore, the graph structure eliminates noise and optimally structures the data, preventing the LLM from having to deduce complex connections.
The Foundational Pillars of a High-Performance KG for RAG
Building an effective KG for RAG requires adherence to two strategic concepts: Taxonomy and Ontology.
Taxonomy with The Structure of Labels
Taxonomy defines the clear hierarchical structure of your labels. It dictates the categories and classifications for your data entities. This step is critical for retrieval. For instance, instead of a single label “Product,” a robust taxonomy uses “Product > Component > Sensor Model > Version 2.1.” This structure enables multi-labeling with exceptional precision. Highly detailed labels ensure that only the exact required context is retrieved during the RAG process.
Ontology with The Logic of Relationships
Ontology establishes the logic and meaning of the relationships that connect the nodes. It defines the ‘why’ and ‘how’ of the links between data points. Ontology ensures the reasoning schema is accurate. A relationship is explicitly defined, such as: (Product X) [IS_MANUFACTURED_AT] (Plant Z). This definitive relationship cannot be misinterpreted by the LLM. It dictates the business or cognitive logic the RAG system must follow when synthesizing a response.
Building a Strategic RAG Solution: The KG Roadmap
Implementing a high-performance RAG system with Knowledge Graphs follows a systematic roadmap. This process ensures the creation of a robust, tailored reasoning schema:
- Structure the Labels (Taxonomy): Define all potential categories and subcategories relevant to the business domain.
- Create Nodes with Refined Chunks: Decompose source documents into the most atomic, relevant information segments possible. Each node should represent a singular fact.
- Link Nodes and Labels: Apply multi-labeling to the nodes with precision. Greater labeling density equals better granularity, thus leading to superior semantic singularity.
- Create the Relationships (Ontology): Explicitly define and establish the logical connections (edges) between the relevant nodes. This step formalizes the organizational or domain knowledge, as further detailed in our article on (Ontology > see Episode 7: Knowledge Graph, storage and retrieval). .
Visualization tools, such as Mind Maps connected to a graph database, prove almost essential for this stage. These tools allow developers and domain experts to properly model the complex relationships visually. This visualization capability significantly accelerates the achievement of semantic singularity. And if you use correctly RAG with Knowledge Graphs, you’ll build a reasoning schema tailored to your use case.
Conclusion: The Strategic Imperative of Contextual Accuracy
The success of RAG is not a matter of trying more solutions; it is a question of architectural choice. While vector embeddings offer convenience, they introduce inherent noise. Knowledge Graphs, therefore, represent a strategic pivot. They enforce the necessary structure through robust Taxonomy and explicit Ontology. This structure guarantees that the RAG system operates on a precise, noise-free reasoning schema tailored to the specific business use case.
The final objective transcends merely answering questions. Mastering RAG with Knowledge Graphs enables the creation of an operational intelligence layer. This layer delivers definitive answers, accelerates complex decision-making, and significantly reduces operational risk. Notably, enterprises that adopt this architectural rigor will gain a measurable competitive advantage. They move beyond simple LLM interaction toward verifiable, actionable intelligence at scale.